Haluatko tietää ja tutkia, miten eduskunta on keskustellut viime vuosikymmeninä työttömyydestä, Natosta tai sukupuolivähemmistöistä? Ei hätää – enää ei ole pakko mennä lukemaan loputonta pinoa pöytäkirjoja. Tampereen yliopistossa toiminut Demokratian äänet -tutkimushanke (2017–2022) on koonnut tietokannan, jossa on tällä hetkellä pöytäkirjat vuosilta 1980–2021 ja rakentanut sen päälle helppokäyttöisen hakukoneen, joka on nyt kaikkien yliopistolaisten käytettävissä. Tällä sivustolla kerromme lisää hankkeestamme ja ennen kaikkea siitä, miten parhaiten pääset käyttämään hakukonetta oman tutkimuksesi tarpeisiin.
Sisältö
Hakukoneemme on verkkopohjainen työkalu, joka hakee osumia suuresta tekstitietokannasta avainsanojen mukaan. Esiprosessoinnin ansiosta se pystyy kuitenkin tekemään monimutkaisempia ja tarkempia hakuja kuin moni muu järjestelmä.
Tavallisia tekstihakuja haittaa usein se, että haluttu sana voi esiintyä eri muodoissa ja hakuehto osuu usein vain osaan niistä. Hakusana "peruna" ei ehkä löydä muotoa "perunat", ja jos löytääkin, niin "perunoita" saattaa jäädä pois. Meidän aineistossamme tällaista ongelmaa ei ole, koska kaikkien sanojen perusmuodot on tunnistettu ja säilyvät itse sanojen kanssa. "Peruna" siis löytää kaikki mahdolliset muodot: "perunat", "perunoita" ja jopa "perunoillannehan". Hakusana voi sisältää mahdolliset yhdyssanat tai karsia ne pois: voi hakea sohvaperunoita ja ruokaperunoita, perunajauhoa ja perunamuussia tai sitten pelkkää perunaa.
Kun kaikki muodot ovat tunnistettavissa, onnistuu myös niiden valikoiminen ja rajaaminen. Haku voi paikantaa vain perunan monikkomuodot, vain sen partitiivimuodot tai jopa sen ainoan syötetyn sanamuodon. Sama koskee verbejä, adjektiiveja ja muita sanaluokkia: esim. kertoa-verbin voi hakea vaikka minä-imperfektimuodoissa, jotka ovat "kerroin" ja "en kertonut". Verbin voi sitten ottaa pois, jolloin haku laajentuu kaikkien verbien imperfektimuotoihin. Hakuehtoja voi siis tarkentaa ja yleistää loputtomiin riippuen vain siitä, kuinka paljon lukemista ne aiheuttavat.
Kielellisten vaatimusten lisäksi hakuja ohjaa myös se, kuka, minkä puolueen edustaja ja milloin on lausunut tietyn virkkeen. Täysistuntojen olosuhteet näkyvät aina hakutulosten yhteydessä ja osa niistä voi toimia suoraan hakuehtoina. Uusimpia tekstejä on käsitelty niin tarkasti, että jopa kyseisen pöytäkirjan sivunumero on tiedossa ja löydettyä tekstiä voi käydä heti katsomassa alkuperäisessä ympäristössä.
Tätä toimintoa ei kuitenkaan tarvitse käyttää joka kertaa, sillä myös hakukone pystyy näyttämään kunkin tuloksen seuraavia ja edeltäviä virkkeitä: kontekstia voi hakea vaikka pöytäkirjan alkuun asti. Eräs hakumoodi ottaa kontekstinkin huomioon hakemalla hakusanojen joukkoa niin, että ne eivät ole edes samassa virkkeessä, vaan niiden välillä voi olla tietty määrä "asiattomia" virkkeitä. Hakusanojen yhdistäminen AND- ja OR-ehdoilla on tietysti mahdollista joka tapauksessa; olemassa on myös NOT-ehto, joka tarkoittaa "mikä tahansa sana paitsi tällainen".
Hakemisen lopuksi tulokset saa aina tallentaa HTML- tai CSV-muotoon jatkokäyttöä varten. Halutessaan niistä voi jopa muodostaa uuden kokoelman, joka käyttäytyy sitten täysin samalla tavalla kuin koko aineisto. Tämä toiminto auttaa tilanteissa, joissa ensimmäinen haku tuottaa alikorpuksen, esim. kaikki avainsanan esiintymät, jatkotutkimusta varten. Sitten tulevien hakujen ei tarvitse poimia samaa avainsanaa koko korpuksesta, eikä vastaava ehto esiinny niissä enää.
Virallisesti sanoen hakukone pystyy:
Hakukone ei osaa:
Tällaisia tehtäviä voidaan kuitenkin ohjelmoida hakukoneen ulkopuolella jäsennetyn aineiston avulla.
Siirry järjestelmään (edellyttää erillistä käyttäjätunnusta)
Jäsennetty pöytäkirja-aineisto, 1980–2021
Hankkeessa tehty tutkimus perustuu kahteen suureen aineistoon: entisten kansanedustajien muistitietohaastatteluihin (1988–2018, ei julkisesti saatavilla) ja eduskunnan täysistuntojen pöytäkirjoihin (1980–2021). Molemmat ovat erittäin rikkaita ja laadukkaita poliittisen puheen lähteitä, sillä tekstit muutetaan tuotantovaiheessa yleiskieleksi ja virheet ovat aineiston kokoon nähden hyvin harvinaisia.
Lisäksi kaikki tekstit on käsitelty TurkuNLP-dependenssijäsentimellä. Tämä työkalu analysoi tekstejä virketasolla tunnistamalla kunkin sanan perusmuodon, sanaluokan, taivutuksen (eli kieliopilliset ominaisuudet) ja mahdollisen syntaktisen roolin. Virkkeestä syntyy myös Universal Dependencies -periaatteiden mukainen dependenssipuu, jossa jokainen sana muodostaa vain yhden yhteyden toisen kanssa: adjektiivit liittyvät määrittämiinsä substantiiveihin, predikaatit liittyvät subjekteihin jne. Morfologisia ja kieliopillisia piirteitä tunnistetaan ymmärrettävästi paremmalla tarkkuudella kuin syntaktisia.
Jäsennysten säilyttäminen alkuperäisten virkkeiden kanssa mahdollistaa sellaisia hakuja, joita moni järjestelmä ei tue, ja tarjoaa arvokasta kielellistä tietoa syvempää tutkimusta varten. Yksi hankkeen tuotoksista onkin tekstihakujärjestelmä, joka hakee sanoja ja niiden yhdistelmiä kohdeaineistoista.
Andrushchenko, M., Sandberg, K., Turunen, R., Marjanen, J., Hatavara, M., Kurunmäki, J., Nummenmaa, T., Hyvärinen, M., Teräs, K., Peltonen, J. & Nummenmaa, J. (2021). Using parsed and annotated corpora to analyze parliamentarians' talk in Finland. Journal of the Association for Information Science and Technology 73(2), 288–302. DOI: 10.1002/asi.24500
Hakujärjestelmän lyhyen esittelyn lisäksi tämä julkaisu sisältää kolme tapaustutkimusta: 1) vallan ymmärryksestä entisten kansanedustajien suullisissa haastatteluissa; 2) eri ismi-sanojen esiintymien ajallisesta kehityksestä eduskunnan täysistuntokeskusteluissa ja ismien yhteisesiintymistä; 3) kertomusten tunnistamisesta sääntöpohjaisella menetelmällä, joka perustuu valikoituihin kieliopillisiin ja semanttisiin merkkeihin. Nämä aiheet saivat enemmän huomiota myöhemmissä artikkeleissa.
Hyvärinen, M., Latvala-Harvilahti, P. & Andrushchenko, M. (2021). Määräysvalta vai mahdollisuus? Valta kansanedustajien muistitietohaastatteluissa. Politiikka 63(4), 349–372. DOI: 10.37452/politiikka.98555
Artikkeli tutkii vallan käsityksen tulkintoja kansanedustajien muistitietohaastatteluissa: kenelle valta kuuluu, miten sitä saadaan ja mitä se mahdollistaa. Huomioon otetaan myös vallan luonne (power to, power over, power with) sekä relevantit yhdyssanat (vaikutusvalta, arvovalta). Artikkelin aineisto on poimittu hakemalla vallan esiintymiä jäsennetyistä teksteistä.
Hatavara, M., Kurunmäki, J. & Andrushchenko, M. (2022). Telling and retelling a historical event: the collapse of the Soviet Union in Finnish parliamentary talk. Scandinavian Journal of History 47(1), 106–127. DOI: 10.1080/03468755.2021.2019105
Artikkeli näyttää, miten Neuvostoliiton romahtaminen esiintyy eduskunnan täysistuntopuheissa ja entisten kansanedustajien haastatteluissa ennen tapahtumaa, sen aikana ja sen jälkeisellä aikakaudella. Tapaukset paikannettiin etsimällä kummastakin aineistosta Neuvostoliiton esiintymiä verbin kanssa, mikä tuotti myös uusia sopivia verbejä alussa oletettujen lisäksi (romahtaa, kaatua, hajota jne.). Haku toistettiin lisättyjen verbien kanssa ja tuloksista poistettiin ne, joissa verbi sattui esiintymään itsenäisesti ilman yhteyttä Neuvostoliittoon.
Tämä ohje esittelee Voices of Democracy -hankkeessa toteutettua hakujärjestelmää, joka paikantaa avainsanoja ja niiden yhdistelmiä tekstiaineistoissa. Tekstit on käsitelty morfosyntaktisella jäsentimellä, mikä mahdollistaa sanojen löytämisen eri taivutusmuodoissa. Jäsennetty tieto tukee erittäin täsmällisiä ja joustavia hakuja, vaikka vastakohtana ovat vaikea kyselykieli ja huonosti ennakoitavat hakutulokset. Hakujärjestelmän käyttö muistuttaa jonkin verran kirjaston verkkopalvelua. Käyttäjä valitsee kohdeaineistot, sitten syöttää haettavan tekstin ja päättää metadataan perustuvista rajauksista. Tässä prosessissa hän voi käyttää apuna aikaisemmin tekemiään hakuja. Onnistuneen haun jälkeen tulokset saapuvat taulukkomuodossa, jossa solut sisältävät tekstin lisäksi metadatan sekä virkkeen jäsennyksen. Tuloksia selattuaan käyttäjä pääsee tallentamaan ne erilliseen tiedostoon ja käynnistämään uuden haun.
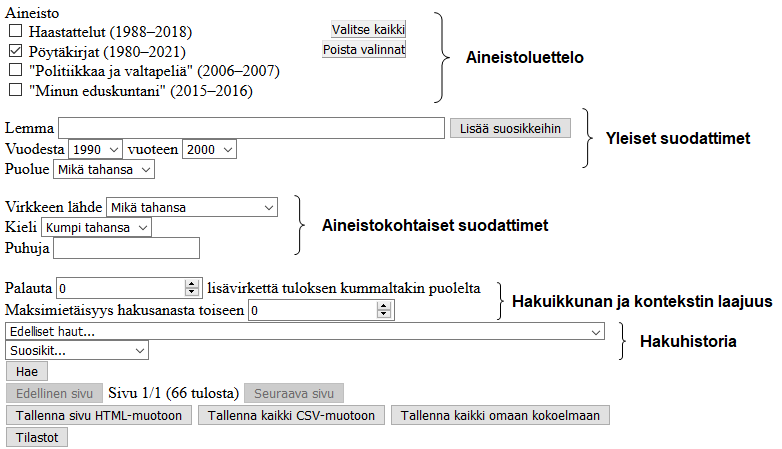
Vuorovaikutus hakujärjestelmän kanssa tapahtuu käytännössä yhdellä sivulla: hakulomakkeen (kuva 1) alla ilmestyy löydetty sisältö.
Ohje etenee tavallaan hakusivun ylhäältä alas ja kuvaa niitä elementtejä, joiden käyttö ei ole suoraviivaista. Hakusuodattimista joustavin ja samalla vaikein on lemman hakurivi, joka määrittelee haettavat sanat, niiden osat, tyypit tai yhdistelmät. Sen toimintaa esitellään kohdassa 2; aiheen monimutkaisuuden vuoksi siitä annetaan lisää esimerkkejä tekstin lopussa, kohdassa 5. Hakutulosten toimittamista, selaamista ja lisävirkkeiden hakemista käsitellään kohdassa 3. Kohta 4 kertoo lyhyesti tulosten tallentamisesta eri muotoihin.
Joka kysely koostuu sanakohtaisista elementeistä, jotka kuvaavat sanoja erikseen. Kun elementtiä on monta, kysely etsii virkkeitä, joissa esiintyy ainakin yksi niistä. Käyttäjä voi kuitenkin vaatia muutaman elementin esiintymistä samassa virkkeessä käyttämällä lainausmerkkejä. Eli kysely "SE1 SE2" SE3 "SE4 SE5" käytännössä tarkoittaa (SE1 and SE2) or SE3 or (SE4 and SE5) ja palauttaa kaikki virkkeet, joissa esiintyvät joko SE1 ja SE2 yhdessä, tai SE3, tai sekä SE4 että SE5. Lisäksi sanan voi poistaa hakutuloksista laittamalla huutomerkin sen eteen. Lainausmerkkien sisällä tämä koskee vain niiden sisäehtoa ja ulkopuolella koko hakua. Tällä tavalla voidaan ilmaista mm. seuraavia hakuja:
| Haku | Tarkoitus |
|---|---|
| SE1 SE2 SE3 | SE1 or SE2 or SE3 |
| "SE1 SE2 SE3" | SE1 and SE2 and SE3 |
| "SE1 SE2" "SE3 SE4" | (SE1 and SE2) or (SE3 and SE4) |
| "SE1 SE2" "SE3 !SE4" | (SE1 and SE2) or (SE3 and (not SE4)) |
| "SE1 SE2" SE3 !SE4 | ((SE1 and SE2) or SE3) and (not SE4) |
| SE1 "SE2 SE3 !SE4" "SE5 SE6" !SE7 | (SE1 or (SE2 and SE3 and (not SE4)) or (SE5 and SE6)) and (not SE7) |
| SE1 SE2 !SE3 !SE4 | (SE1 or SE2) and (not SE3) and (not SE4) |
Sanaa määriteltävä elementti on muodoltaan osiin jaettava merkkijono, jonka erotin on |. Ensimmäinen osa on aina lemmaa eli perusmuotoa varten, toinen kertoo lemman tyypistä ja jälkimmäiset määrittävät sanan ominaisuuksia, kuten substantiivin sijamuotoa.
Tarkoitus yleensä on, että vaikka tekstissä olevilla sanoilla on usein eri taivutusmuotoja, niillä saattaa olla sama perusmuoto. Hakuja tehdään lähtökohtaisesti juuri tämän perusmuodon perusteella niin, että kaikki taivutusmuodot ovat sopivia tuloksia. Ominaisuuksilla voi sitten estää joidenkin muotojen palauttamista ja näin tarkentaa alkuperäistä hakua.
Jos halutaan kuitenkin etsiä ainoastaan tiettyä sanamuotoa, ilman rinnakkaisia taivutusmuotoja, sen jälkeen laitetaan huutomerkki. Tällöin ei tarvitse lisätä mitään muita ehtoja.
Yksittäinen asteriski lemma-osassa tarkoittaa puuttuvaa, rajoittamatonta lemmaa. Tämän osan voi myös jättää tyhjäksi: |type=VERB sekä *|type=VERB tarkoittavat ”mikä tahansa verbi”.
Hakujärjestelmä pitää lemmaa säännöllisenä lausekkeena, mikä laajentaa hakumahdollisuuksia. Tämän tiedoston lopusta löytyy muutama esimerkkikysely, joista viimeinen esittelee regex-tyylistä hakua.
Ehkä tärkein seuraus tästä on se, että järjestelmä huomioi kaikki sanat, joissa haettava lemma esiintyy alussa, lopussa tai keskellä: esim. valta tuottaa mm. ”väkivalta” ja ”valtava”. Tämä voi olla hyödyllistä etsittäessä vaikka tiettyä päätettä, mutta saattaa myös tuoda odottamattomia tuloksia, erityisesti kun lemma on lyhyt (ei tarkoittaa ehkä kieltoverbiä, mutta käytännössä esiintyy myös substantiivissa ”veitsi” ja monissa muissa).
Lemman sijainti määritellään kahdella apumerkillä. Sirkumfleksi (^) ennen lemmaa vaatii, että se on sanan alussa, mutta ei välttämättä pääty sen lopussa: ^valta sisältää ”valtava”, mutta ei ”väkivalta”. Tämän merkin käyttö kaikissa hakusanoissa nopeuttaa kyselyn suorittamista.
Dollarin merkki ($) lemman jälkeen vaatii taas, että sana loppuu siihen: valta$ sisältää ”väkivalta”, mutta ei ”valtava”. Molempien merkkien samanaikainen käyttö varmistaa, että lemma kattaa koko sanan.
Henkilökohtaisten asetusten avulla nämä merkit voi lisätä automaattisesti ja kirjoittaa hakuehtoja ilman niitä (tästä vastaa valintanappi kuvassa 4). Silloin hakusana ei voi enää muodostaa osaa sanasta, koska lisätyt merkit kiinnittävät sen aina sanan alkuun ja loppuun. Jos tämä asetus ei ole päällä, käyttäjä voi saada sen sijaan ylimääräisiä yhdyssanoja hakutuloksiksi merkkien unohtuessa.
Lemman tyyppi, joka yleensä seuraa ensimmäistä osaa, on itse asiassa kyseisen sanan luokka. Mahdolliset tyypit ovat NOUN (substantiivi), PROPN (erisnimi), PRON (pronomini), ADJ (adjektiivi), AUX (apuverbi), VERB (verbi), ADV (adverbi), ADP (pre- ja postpositiot), NUM (perusluku), CONJ, SCONJ (konjunktiot), INTJ (interjektio), PUNCT (välimerkitys) ja X (jäsentämätön, usein vieraskielinen sana). Kuten jo mainittu, tyyppi ilmaistaan muodolla type=NOUN (tai muu sanaluokka).
Jos lemman tyyppi on olemassa, sen jälkeen voi lisätä vastaavan sanaluokan ominaisuuksia ja niiden arvoja. Ne riippuvat siis lemman tyypistä: verbejä voi etsiä vaikka tietyssä aikamuodossa, jolla ei ole enää merkitystä substantiivin tai pronominin yhteydessä. Jokaisen tyypin piirteet sallittuine arvoineen löytyvät seuraavasta luvusta. Ominaisuudet ovat vapaaehtoisia, ja kun ne otetaan huomioon samaan aikaan, jokaisen uuden ehdon lisääminen vähentää tulosten määrää; niiden järjestyksessä ei kuitenkaan ole vaikutusta. Ominaisuudella voi olla useampi vaihtoehtoinen, pilkulla erotettava arvo.
Nämä kyselymuodot ovat siis oikein:
lemma|type=TYPE1|omin1=arvo1|omin2=arvo2 jne.
lemma|type=TYPE1|omin1=arvo1,arvo2|omin2=arvo3,arvo4
lemma
lemma!
lemma!|type=TYPE1
|type=TYPE1|omin1=arvo1
*|type=TYPE1|omin1=arvo1
Nämä muodot ovat taas väärin:
lemma|omin1=arvo1|omin2=arvo2 (puuttuu tyyppi)
lemma|TYPE1|omin1=arvo1|omin2=arvo2 (puuttuu ”type=”)
TYPE1|omin1=arvo1|omin2=arvo2 (puuttuu erotin ennen tyyppi-osaa, vaikka mitään lemmaa ei annettu)
lemma|type=TYPE1|arvo1|arvo2 (puuttuu ominaisuuden nimi)
lemma|omin1=arvo1|omin2=arvo2|type=TYPE1 (tyyppi ei tule heti lemman jälkeen)
Tavallisia hakuehtoja voi kuvata seuraavilla esimerkeillä:
tulla : tulla-verbi kaikkine taivutusmuotoineen.
tulla! : ainoastaan sana ”tulla”, eli verbin perusmuoto.
!tulla! : kaikki mahdolliset sanat, paitsi ”tulla” perusmuodossa. (Tässä tapauksessa huutomerkillä on kaksi eri merkitystä: se määrittelee vain yhden sanamuodon ja poistaa sen hakutuloksista.)
tule : ei onnistu, koska kyseessä on lemmahaku ja ”tule” ei ole minkään sanan perusmuoto. Palauttaa kuitenkin mm. ”tuleva” ja ”tulevaisuus”, joiden perusmuotoihin ”tule” sisältyy.
^kunta$ : ”kunta” taivutusmuotoineen.
^kunta : ”kunta”, ”kuntapolitiikka”, ”kuntatalo” ja muut taivutusmuotojen kanssa.
kunta$ : ”kunta”, ”eduskunta”, ”seurakunta” ja muut taivutusmuotojen kanssa.
Yhdyssanojen hakeminen on joskus ongelmallista, kun niiden osat on erotettu lemman sisällä ristikkomerkillä (#). Tämä merkitsee usein sanojen johtamista niissäkin tapauksissa, joita ei katsota yhdyssanoiksi, kuten ”edus#kunta”. Jos alkuperäinen vartalo on itsenäinen sana, se on lemmassa aina perusmuodossaan, joten ristikkomerkin poisto ei aina auta: sanasta ”maljanjuonti” tulee lemma ”malja#juonti”, joka ilman ristikkomerkkiä eroaisikin itse sanasta. Yhdyssanaa pystyy hakemaan vain sellainen hakuehto, joka vastaa sen jäsennystä tai ainakin sen alku- tai loppuosaa.
Tätä tarkoitusta varten hakujärjestelmä jatkuvasti suorittaa ”puoliautomaattista” täydennystä, kun lemman hakurivi on käytössä. Sen alla esiintyvässä taulukossa näkyvät aineiston yleisimmät sanat, jotka vastaavat kohdistimen alla olevan hakusanan tämänhetkistä muotoa (kuva 2). Jos tarkoitettu sana ei löydy niistä, kannattaa ottaa muutama kirjain pois, kunnes se näkyy taulukossa. Taulukon muoto on aina sanan alkuperäinen jäsennys, jolla sitä voi hakea. ^- ja $-merkkien käyttöasetus vaikuttaa taulukon sisältöön täysin samalla tavalla kuin varsinaisessa haussa. Vain 35 yleisintä sanaa näytetään, mikäli osumia on tätä enemmän.

Annettaviin vaihtoehtoihin liittyvät aina niiden esiintymismäärät, joiden lähteenä toimii haastatteluaineiston vanhempi versio. Nämä luvut tarkoittavat, kuinka monta virkettä vastaavan sanan kanssa hakuehto tuottaisi. Muiden hakuehtojen ja hakusanojen vaikutusta ei oteta huomioon, sillä ne vähentävät tulosten määrää (yhteen hakusanaan verrattuna) ennustamattomalla tavalla. Lukumäärät eivät liity myöskään pöytäkirja-aineistoon, vaikka siinäkin yhteydessä ne auttavat arvioimaan eri sanojen suhteellista yleisyyttä.
Alkuperäisen lemman selvittämiseksi voi vaihtoehtoisesti hakea kyseistä sanaa jossakin tietyssä muodossa huutomerkin avulla. Kun ainakin yksi vastaava virke löytyy, sen sanat-sarakkeesta voi katsoa, mikä lemma tällä sanalla on, ja muokkaa hakuehtoja sen mukaan.
| Ominaisuus | Arvot | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Nom | Par | Gen | Acc | Abl | Ade | All | Ela | Ine | Ill | Ess | Tra | Ins | Abe | Com |
| Number | Sing | Plur | |||||||||||||
| Number[psor] | Sing | Plur | |||||||||||||
| Person[psor] | 1 | 2 | 3 |
Number[psor] ja Person[psor] koskevat omistusliitettä, jos substantiivi loppuu sillä. Ne eivät esiinny erisnimien kanssa.
PROPN:
| Ominaisuus | Arvot | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Nom | Par | Gen | Acc | Abl | Ade | All | Ela | Ine | Ill | Ess | Tra | Ins | Abe | Com |
| Number | Sing | Plur |
| Ominaisuus | Arvot | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Nom | Par | Gen | Acc | Abl | Ade | All | Ela | Ine | Ill | Ess | Tra | Ins | Abe | Com |
| Number | Sing | Plur | |||||||||||||
| PronType | Dem | Rel | Prs | Ind | Int | Rcp | |||||||||
| Person | 1 | 2 | 3 |
Person on olemassa vain persoonapronomineilla (PronType=Prs).
ADJ:
| Ominaisuus | Arvot | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Nom | Par | Gen | Acc | Abl | Ade | All | Ela | Ine | Ill | Ess | Tra | Ins | Abe | Com |
| Number | Sing | Plur | |||||||||||||
| Degree | Pos | Cmp | Sup | ||||||||||||
| NumType | Ord |
Degree puuttuu joistakin adjektiiveista, kuten ”sellainen”, sekä järjestysluvuista. NumType on taas järjestyslukujen ominaisuus.
AUX ja VERB:
| Ominaisuus | Arvot | |||
|---|---|---|---|---|
| Mood | Ind | Cnd | Imp | Pot |
| Tense | Pres | Past | ||
| VerbForm | Fin | Part | Inf | |
| InfForm | 1 | 2 | 3 | |
| Voice | Act | Pass | ||
| Number | Sing | Plur | ||
| Person | 1 | 2 | 3 |
Number ja Person ovat olemassa vain aktiivissa pääluokassa (Voice=Act). Pääluokka, modus ja aikamuoto eivät koske infinitiivimuotoja (VerbForm=Fin), jotka saavat sen sijaan InfForm-arvon.
Partisiipin (VerbForm=Part) ominaisuudet ovat taas adjektiivin kaltaisia:
| Ominaisuus | Arvot | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Nom | Par | Gen | Acc | Abl | Ade | All | Ela | Ine | Ill | Ess | Tra | Ins | Abe | Com |
| Number | Sing | Plur | |||||||||||||
| Degree | Pos | Cmp | Sup | ||||||||||||
| PartForm | Pres | Past | Agt | Neg | |||||||||||
| Voice | Act | Pass |
Jäsennin kutsuu sanoja partisiipeiksi myös silloin, kun ne kuuluvat verbin liittomuotoon, kuten ”on lukenut”. Sen takia verbin aikamuoto voi olla joko preesens tai imperfekti. Muiden aikamuotojen hakemiseksi jäsentimen annotaatiota laajennetaan erillisellä menetelmällä, joka pyrkii tunnistamaan monimutkaisten verbirakenteiden aikamuotoja ja moduksia. Se tarjoaa seuraavia ominaisuuksia haettavaksi:
| Ominaisuus | Arvot | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tense2 | Pres | Impf | Perf | Pperf | Kond | Kperf | Pot | Pperf | Impr | Inf |
| InfForm2 | 1 | 2 | 3 | 5 | ||||||
| Sign2 | + | - | ||||||||
| Voice2 | Act | Pass | ||||||||
| Number2 | Sing | Plur | ||||||||
| Person2 | 1 | 2 | 3 |
Tense2 on siis aikamuodon ja moduksen yhdistelmä, jonka arvot tarkoittavat (taulukon järjestyksessä) neljää indikatiivin aikamuotoa, kahta konditionaalin aikamuotoa, kahta potentiaalin muotoa, imperatiivin preesensmuotoa ja infinitiivejä. Sign2 mahdollistaa erikseen myönteisten ja kielteisten verbi-ilmaisujen hakemista.
ADP:
| Ominaisuus | Arvot | |
|---|---|---|
| AdpType | Post | Prep |
| Ominaisuus | Arvot | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Nom | Par | Gen | Acc | Abl | Ade | All | Ela | Ine | Ill | Ess | Tra | Ins | Abe | Com |
| Number | Sing | Plur | |||||||||||||
| NumType | Card |
ADV, CONJ, SCONJ, INTJ, PUNCT, X: ei lisäehtoja
Lisäksi järjestelmä tunnistaa muutaman ominaisuuden, joka ei liity suoraan sanaluokkiin:
| Ominaisuus | Arvot | Tarkoitus |
|---|---|---|
| Reflex | Yes | Sana ”itse”, kun se esiintyy pronominina (PronType ei tällöin ole olemassa) |
| Connegative | Yes | Kaikkien verbien kielteiset preesensmuodot, kuten ”muista” |
| Negative | Yes | Kieltoverbin muodot, kuten ”emme” |
| Foreign | Foreign | Vieraiden kielten sanat, usein ruotsin- ja englanninkieliset |
| Abbr | Yes | Lyhenteet (yleensä adverbit) ja tunnukset (substantiivit tai erisnimet) |
| Typo | Yes | Melko pieni joukko väärin kirjoitettuja sanoja, kuten ”mielummin” |
| Derivation | Inen, Ja, Lainen, Llinen, Minen, Sti, Tar, Ton, Ttaa, Ttain, U, Vs | Sanat, joiden lopussa on vastaava pääte. Niiden lemma on alkuperäisen sanan perusmuoto ilman päätettä, mutta tyyppi pysyy laajennetun sanan mukaisesti: ”opiskeleminen” säilytetään muodossa ”opiskella|type=NOUN|Derivation=Minen” |
| Clitic | Han, Pa, Ko, Kin, Kaan, S | Sanat, joiden lopussa on vastaava liitepartikkeli. Sanalla voi olla useampi arvo samanaikaisesti |
Vielä yksi ei-morfologinen ominaisuus on deprel, joka tarkoittaa sanan syntaktista asemaa virkkeessä. Sen mahdolliset arvot löytyvät osoitteesta https://universaldependencies.org/fi/dep/ ja hakuehdot noudattavat samaa muotoa: deprel=gobj tai (useamman arvon tapauksessa) deprel=nmod,advmod,advcl. Jotkin arvot vastaavat Universal Dependencies -periaatteita enemmän kuin perinteisiä kieliopillisia käsitteitä. Ilmiön monimutkaisuuden vuoksi syntaktisia ominaisuuksia ei tunnisteta samalla tarkkuudella kuin morfologisia.
Edelliset esimerkit koskevat vain yksittäisiä sanoja. Jos etsitään vaikka kaksi sanaa, toinen samanlainen lauseke lisätään ensimmäiseen välilyönnin jälkeen. Lausekkeet katsotaan lainausmerkkien välillä AND-ehdoiksi ja muuten OR-ehdoiksi. Muut rajoitukset, kuten sukupuoli tai ajankohta, toimivat edelleen aina AND-ehtoina. Myös kontekstia voi saada niistä virkkeistä, joissa kaikki muut ehdot täyttyvät.
Sanakohtaiset ehdot eivät kuitenkaan vaikuta useamman sanan sijaintiin virkkeessä tai peräkkäisissä virkkeissä. Järjestelmässä on kaksi ratkaisua, joilla tällaisia hakuja suoritetaan.
Jos sanojen pitää esiintyä samassa virkkeessä peräkkäin tai ainakin tietyssä järjestyksessä, tekstihaku voi löytää sopivia tapauksia. Tekstihaun kohde syötetään puolilainausmerkkien sisälle ja verrataan suoraan virkkeen tekstiin. Tässä muodossa käytetään siis itse sanoja ilman kieliopillisia piirteitä tai muita apumerkkejä, koska nämä eivät esiinny alkuperäisessä tekstissä. Haettava osa toimii kuitenkin edelleen säännöllisenä lausekkeena, joten 'ei tule' tarkoittaa kahta peräkkäistä sanaa, kun taas 'ei.+tule' vaatii myös, että niiden välillä on muuta tekstiä. Tekstihaun osa (tässä vaiheessa vain yksi sallitaan) poistetaan hakurivistä kyselyn valmistelun aikana ja loput käsitellään edellisten sääntöjen mukaisesti. Tekstihakua suositellaan useamman sanan etsittäväksi, koska yhden sanan ominaisuuksia käsitellään tehokkaammin tavallisella lemmahaulla.
Molempien tyyppien yleisimmät lainausmerkit korvataan automaattisesti samoilla merkeillä, joten niitä voi käyttää vapaasti, vaikka ”puolikkaisilla” ja tavallisilla merkeillä onkin eri merkitys. Kyselyn muodostamiseksi on kuitenkin tärkeää, että jokaisella lainausmerkillä on oma pari hakurivin oikeassa paikassa.
Yleensä järjestelmä palauttaa ensimmäiset 1000 virkettä mahdollisimman pian, vaikka hakutuloksia olisi vielä tulossa. Sen takia niiden määrä näkyy muodossa ”1000+”. Selaimen muistissa on silloin enintään 1000 virkettä; kun siirrytään tästä ”paketista” eteenpäin, seuraava annos tulee tietokannasta pienen viivästyksen jälkeen. Samalla päivittyy tulosten määrä, jos tietokanta on suorittanut haun loppuun ja se on jo tiedossa. Sivujen määrä riippuu siitä, kuinka monta virkettä näytetään yhdellä sivulla, eli yksi ”paketti” voi kattaa 5 sivua (200 virkettä per sivu) tai 20 sivua (50 virkettä per sivu). 1000 virkkeen raja on kuitenkin pysyvä.
Jos seuraavat 1000 hakutulosta ovat vielä työn alla, seuraavan sivun lataaminen ei onnistu ja sitä voi yrittää uudestaan muutaman sekunnin jälkeen. Haku voi tuottaa enintään 50000 virkettä, minkä jälkeen ne kaikki ovat ladattavissa ja haun käsittely päättyy.
Vaikka haku olisi jo loppuun suoritettu, kaikkia sen tuloksia ei ladata tietokannasta heti. Takaisin tulevat vasta ensimmäiset 1000, ja saadakseen lisää täytyy siirtyä viimeiselle sivulle ja sieltä eteenpäin. Vain sivujen peräkkäinen katselu on mahdollista, koska muuten käyttäjä tulisi usein hyppäämään saatavilla olevien tulosten ulkopuolelle. Kaikki jo ladatut hakutulokset jäävät selaimeen, kunnes yritetään kokonaan uusi haku. Palaaminen ensimmäisille tulossivuille, jotka on jo saatu tietokannasta aikaisemmin, ei aiheuta muita viivästyksiä kuin taulukon päivittämistä.
Oikeassa yläreunassa olevilla valintaruuduilla (kuva 3) hallitaan tulostaulukkojen sarakkeiden näkyvyyttä. Kun valintaruutu laitetaan pois päältä, samanniminen taulukon sarake poistuu näkyvistä ja toisinpäin. Tämä tiivistää hakutuloksia ja antaa lisää tilaa, erityisesti sanat-sarakkeen tapauksessa, kun kieliopilliset piirteet eivät kiinnosta. Jos samalla sivulla on virkkeitä eri kokoelmista, valintaruutujen valikoima kattaa kaikki näiden kokoelmien kentät. Kunkin sarakkeen näkyvyys vaihtuu tällöin kaikissa taulukoissa, joissa se esiintyy (esimerkiksi teksti-sarake on mukana kaikissa aineistoissa).
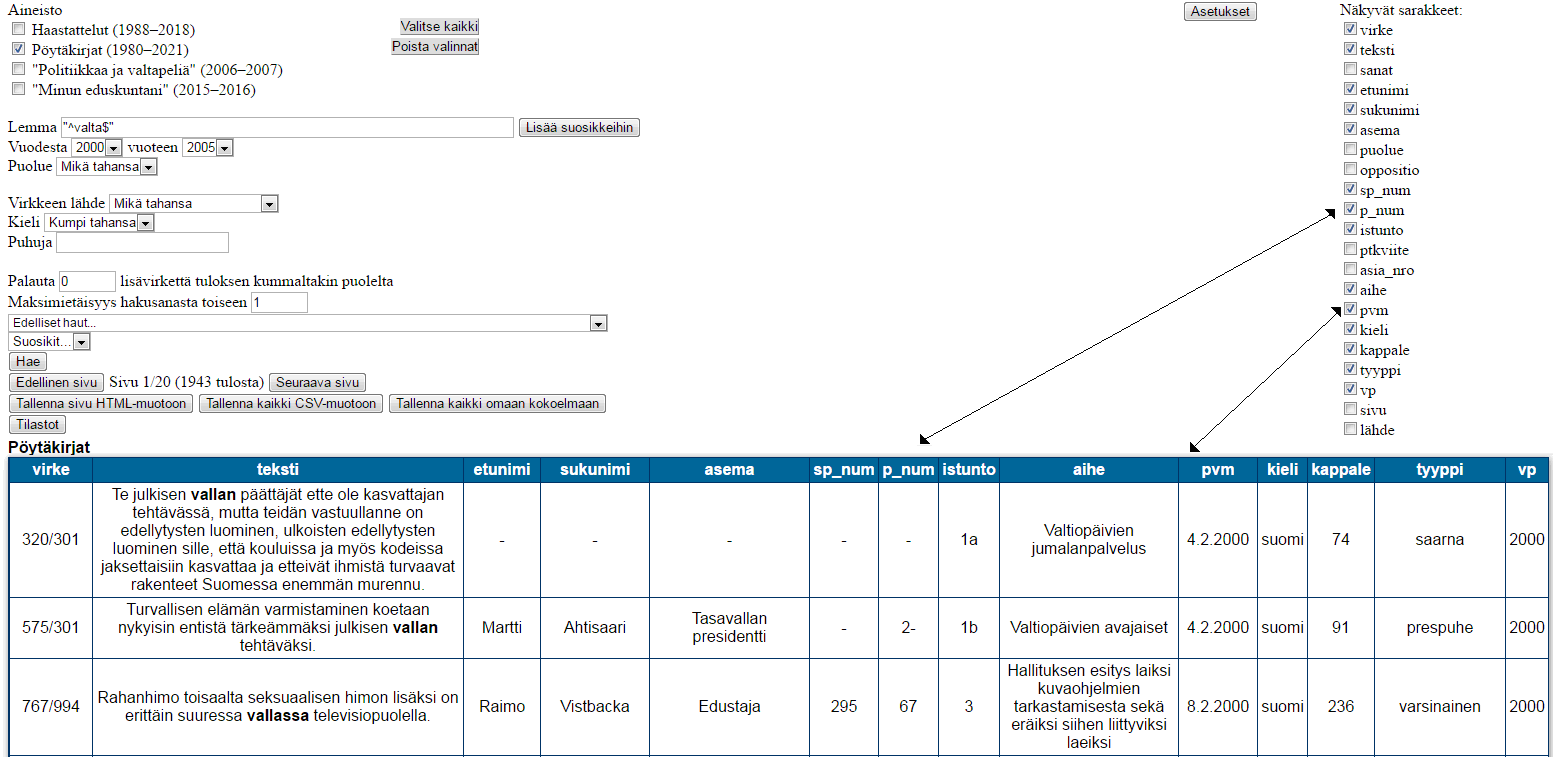
Henkilökohtaisten asetusten avulla (kuva 4) voi etukäteen valita ne sarakkeet, joita ei koskaan tarvitse näyttää. Tällä tavalla piilotetaan vähämerkityksellisiä tietoja ja jonkin verran nopeutetaan hakutulosten näyttämistä. Asetus koskee kuitenkin vain istunnon ensimmäisiä hakuja: jos käyttäjä itse vaihtaa myöhemmin jonkin valintaruudun tilan, se pysyy jatkossa siinä tilassa asetuksesta huolimatta, kunnes hakusivu ladataan uudestaan.
Muilla asetuksilla pääsee muokkaamaan näytettävän hakuhistorian kokoa (10, 25, 50 tai 100 viimeisintä hakua), virkkeiden määrää hakusivulla (25, 50, 100 tai 200) sekä lemman sijaintia sanassa (missä tahansa, sanan alussa, sanan lopussa tai koko sanana).
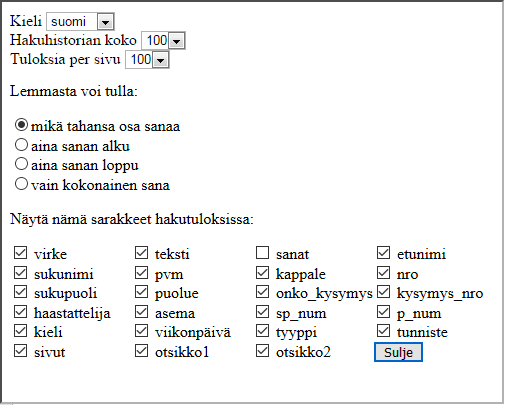
Kaikkien käynnistettyjen hakujen ehdot tallennetaan yhteiseen tiedostoon, josta rakentuu käyttäjän henkilökohtainen hakuhistoria. Hae-painikkeen edessä on pudotusvalikko, jossa näkyvät hänen viimeisimmät hakunsa. Rivin valitseminen täyttää hakulomakkeen samoilla arvoilla, niin että haku voidaan toteuttaa heti uudestaan. Hakuhistorialla on oletuksena rajoitettu pituus, mutta vanhemmatkin hakuehdot arkistoidaan ja niihin voidaan päästä tarvittaessa.
Kun hakurivin sisältö muodostaa usein koko kyselyn tärkeimmän ja monimutkaisimman osan, sen voi siirtää erilliseen suosikkilistaan onnistuneen haun jälkeen. Vaikka lista ei säilytä muita hakuehtoja, sen lemmat ovat pysyviä: niiden poistaminen tapahtuu ainoastaan käyttäjän toimesta hiiren oikealla klikkauksella.
Niiden virkkeen lisäksi, jotka vastaavat annettuja hakuehtoja, on mahdollista selata myös seuraavien ja edeltävien virkkeiden sisältöä. Näitä virkkeitä voi tilata etukäteen ohjaimella, joka sijaitsee kaikkien yleisten sekä aineistokohtaisten suodattimien jälkeen. Pyydetty määrä virkkeitä lisätään kunkin hakutuloksen jälkeen ja ennen sitä. Keskeinen, valituksi tullut virke lihavoidaan tällöin paremman näkyvyyden takia. Tuloksen metadata koskee edelleen keskeistä virkettä eikä välttämättä lisättyjä, ja pelkästään teksti-sarake laajenee. Jos haetut virkkeet olivat lähellä toisistaan, niiden konteksti saattaa aiheuttaa päällekkäisyyksiä: virke A+2 voi olla sama kuin vaikka B-1, riippuen A:n ja B:n numeroista.
Kun sanat etsitään lähellä olevista virkkeistä, kannattaa ottaa käyttöön ”ikkunahaku”, josta vastaa hakulomakkeen viimeinen ohjain (kuva 5). Tässä muodossa haettavat lemmat saavat olla muutaman virkkeen päästä toisistaan, ei välttämättä samassa virkkeessä. Lainausmerkkien muodostamasta AND-lausekkeesta poimitaan ensimmäinen sana, sitten sen ympäriltä etsitään toinen, ja edelleen seuraava sana etsitään edellisten läheisyydestä. Järjestelmä palauttaa ainoastaan ne tapaukset, joissa kaikki lausekkeen lemmat löytyivät. Tässä hakumuodossa järjestelmä tuo samassa tuloksessa kaikki virkkeet ensimmäisestä lemmasta viimeiseen ja lisäksi lihavoi lemmojen mukaan valittuja sanoja. Jos kontekstia pyydettiin haun yhteydessä, virkkeitä lisätään ennen tätä kappaletta ja sen jälkeen. Kun haulla on useampi AND-lauseke, tuloksia poimitaan jokaisesta vuorollaan.
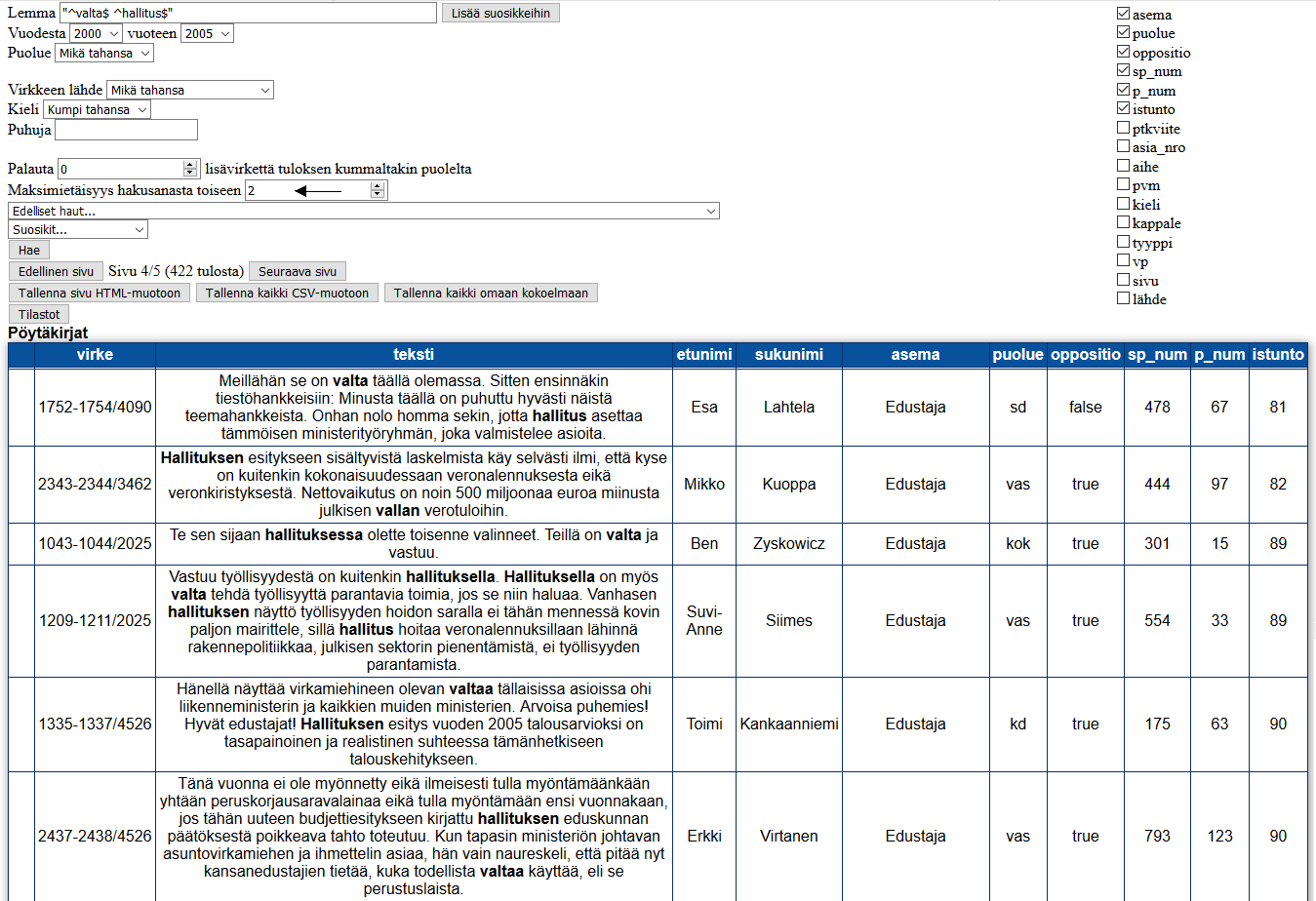
Sanoja etsitään vain siinä järjestyksessä, missä ne on syötetty, ja pitkät sanaketjut ovat aika harvinaisia. Jos tuloksia syntyy liian vähän, kannattaa ehkä poistaa sanoja hakurivistä tai muuttaa niiden järjestystä. Harvinaisemmat sanat vähentävät mahdollisten ja siten myös ”onnistuneiden” sanaketjujen määrää. Tähän vaikuttaa myös käyttäjän antama ikkunan ”leveys”, eli kuinka monta virkettä saa olla kahden hakusanan välillä. Ikkunahaun suorituskyvyn takia se palauttaa aina enintään 1000 ikkunaa (konteksteineen) kerrallaan.
Muut hakuehdot koskevat vain sitä virkettä, josta löytyy ensimmäinen sana; seuraavat sanat etsitään sen läheisyydestä, vaikka niiden sisältämät virkkeet eivät enää täyttäisi alkuperäisiä ehtoja. Jos hakuehdot vaativat esimerkiksi tiettyä henkilöä, ensimmäisen hakusanan sisältyvä virke tulee aina hänen puheenvuorostaan mutta ympärillä olevat saattavat kuulua myös seuraavaan tai edelliseen puheenvuoroon. (Palautetussa tekstissä ensimmäinen hakusana ei ole välttämättä ensimmäisessä virkkeessä: se riippuu täysin siitä, miten seuraavat sanat ovat järjestyneet sen läheisyydessä.) Samalla tavalla tuloksessa näkyvät juuri tämän ensimmäisen virkkeen tiedot, esim. puhuja tai otsikko. Hakutulos ei kuitenkaan saa koostua eri dokumenttien (haastattelujen tai pöytäkirjojen) virkkeistä, eli sanaketjujen haku pysähtyy aina niiden alussa ja lopussa.
Lisätyistä virkkeistä huolimatta lukija haluaakin usein tietää, mistä puhuttiin näkyvän pätkän jälkeen tai ennen sitä. Siksi lisää kontekstia voidaan hakea yksittäisten tulosten osalta myös haun jälkeen. Tämä onnistuu klikkaamalla pienen sarakkeen ennen virkkeen numeroa, joka aina esiintyy heti taulukon alussa (kuva 6). Solussa ilmestyy sitten kaksi nuolta, jotka tuovat yhden lisävirkkeen tekstin alkuun tai loppuun. Niitä voi käyttää toistuvasti, vaikka dokumentin rajoihin asti. Näin haettu konteksti on olemassa vain sivun muotoilussa: se häviää itsestään, kun käyttäjä siirtyy esim. seuraavalle sivulle, eikä sitä voi muuten poistaa. Tästä syystä se tallentuu HTML-muotoon, mutta ei muilla tavoin.
Palautettuja virkkeitä voidaan haun jälkeen tallentaa kolmella eri tavalla: HTML-muotoon, CSV-muotoon tai erilliseen kokoelmaan. Vastaavat painikkeet ovat heti tulostaulukon yllä.
HTML-muotoon tallentuu vain se sivu, joka näkyy selaimessa tallentamishetkellä. Sen tarkoitus on pelkästään toistaa alkuperäisen sivun taulukkomuotoista, helposti selattavaa rakennetta, eikä se sovi syvempään analyysiin. Sivulle tulostuvat kaikki aineistoon sisältyvät sarakkeet, myös käyttäjän piilottamat.
CSV-muotoon tallentuvat kaikki selaimessa olevat tulokset: niiden määrä on yleensä seuraava tuhannen monikerta. Esimerkiksi, jos käyttäjä on päässyt sivulle 13 ja sivulla on 100 tulosta, selain on hakenut tulokset 1001–2000 ja CSV-tiedostoon tulee sitten 2000 tulosta.
Tallentaessaan CSV-muotoon käyttäjä saa ensin valita, mitkä kentät otetaan mukaan. Kukin virke saa CSV-muodossa oman rivin ja kustakin valitusta kentästä tulee oma sarake. Poikkeuksena on sanat-sarake: kun sekin on luonteeltaan taulukkomuotoinen, sanat jäsennyksineen tulostetaan eri riveille jokaisen virkkeen jälkeen. Tiedosto on tarkoitettu katsottavaksi Excelissä, joten sen sisältöä muokataan hiukan Excelin erikoisuuksien vuoksi. Esimerkiksi vinoviivoja korvataan tietyissä tapauksissa keinoviivoilla tai |-merkeillä, koska muuten Excel saattaa tulkita arvon päivämääräksi.
CSV-tiedosto voi sisältää useamman aineiston hakutuloksia samanaikaisesti. Niiden samannimiset kentät (kuten teksti) ohjautuvat tällöin samaan sarakkeeseen, kun taas uniikit kentät tulostuvat erikseen. Jos aineistossa A on kenttä, jota ei ole aineistossa B, tulee vastaava sarake olemaan tyhjä kaikissa B:stä haetuissa tuloksissa. Tämä aiheuttaa isoja aukkoja tiedostossa, jotka kasvattavat jonkin verran sen kokoa. Saman aineiston tulokset esiintyvät tiedostossa peräkkäin.
Kun hakutulokset tallennetaan omaan kokoelmaan, tietokannassa luodaan uusi osio, jonka rakenne on täysin sama kuin alkuperäisissä aineistoissa. Uusi kokoelma on siis pöytäkirja- tai haastatteluaineiston pienempi versio, joka sisältää vain viimeisimmän haun tulokset ja josta voi hakea uudelleen aivan kuin koko aineistosta. Tämä tarkoittaa käytännössä hakutulosten suodattamista.
Jokaisella käyttäjällä voi olla maksimissaan 10 omaa kokoelmaa. Ne ilmestyvät heti luomisen jälkeen sivun alussa olevassa aineistoluettelossa, josta ne voidaan myös poistaa. Muiden käyttäjien tai alkuperäisten aineistojen poistaminen ei tietenkään ole mahdollista.
Uuden kokoelman kanssa voi siis työskennellä samalla tavalla kuin alkuperäisen, paitsi että kontekstin hakeminen sieltä ei yleensä onnistu. Kokoelman sisältö koostuu aiemman haun tuloksista, joiden välissä on tavallisesti aukkoja, kun taas konteksti tulee heti seuraavista ja edeltävistä virkkeistä. Toiminto onnistuu kuitenkin silloin, kun peräkkäiset virkkeet päätyvät kokoelmaan sattumalta.
"nyt! |type=VERB|Tense=Past" : mikä tahansa verbi imperfektissä ja sana ”nyt” samassa virkkeessä. Ensimmäisen sanan vaihtoehtoinen muoto on nyt!|type=ADV.
"ei! tarvitse!" : sanat ”ei” ja ”tarvitse” samassa virkkeessä, mutta ei välttämättä yhteydessä.
kansa|type=NOUN|Case=Nom valta|type=NOUN|Case=Par : ”kansa” subjektin asemassa tai ”valta” objektin asemassa. Sanat voivat olla niin yksikössä kuin monikossa.
"kansa|type=NOUN|Case=Nom|Number=Sing tarvitsee!|type=VERB|Tense=Pres" arvoinen|type=ADJ "puolue|type=NOUN|Number=Plur vaikuttaa|type=VERB" : monimutkaisempi kysely. Tämä palauttaa kaikki virkkeet, joissa esiintyy joko
- substantiivi ”kansa” yksikön nominatiivissa, eli nimenomaan ”kansa”, ja verbi ”tarvitsee” juuri tässä muodossa, tai
- adjektiivi ”arvoinen” missä tahansa muodossa, tai
- substantiivi ”puolue” missä tahansa monikon sijamuodossa, vaikka ”puolueet” tai ”puolueissa”, ja verbi ”vaikuttaa” ilman muita edellytyksiä.
nyt! sanoi! !kertoi! : joko ”nyt” tai ”sanoi”, mutta joka tapauksessa ilman ”kertoi”.
'ei kertonut' "^tulos$ sitten!" : sanat ”sitten”, ”tulos” (missä tahansa muodossa) ja ”ei kertonut” (peräkkäin) samassa virkkeessä. Ensimmäinen osa, verbin kieltomuoto, toimisi tehokkaammin muodossa kertoa|type=VERB|Sign2=-|Tense2=Impf|Person2=3|Voice2=Act. Tämä paikantaa nekin imperfektin esiintymät, joissa partisiippi ei tule heti kieltoverbin jälkeen, kuten tekstihaun ehto edellyttää.
^t[a-z][a-z]li$|type=NOUN : regex-tyylinen kysely. Etsii substantiivit ”tuuli”, ”tulli”, ”tyyli” ja kaikki muut, joissa toinen ja kolmas kirjain vaihtelee. Sirkumfleksi kyselyn alussa vaatii, että seuraavat merkit ovat välttämättä lemman alussa.
Seuraava teksti esittelee hakusanojen vaikutuksia hieman eri tavalla. Kymmenen esimerkkivirkkeen jälkeen tulee taulukko, jonka hakuehdot kohdistuvat näihin virkkeisiin. Toisessa sarakkeessa luetellaan kutakin hakuehtoa vastaavat virkkeet; suluissa annetaan virkkeen ensimmäinen sana, johon hakuehto osuu.
1) Uusi kirja poliittisesta ja yhteiskunnallisesta vallasta on ilmestynyt Helsingissä tällä viikolla.
2) Teos syntyi epävarmuuden ja pelon vallitsemana aikana.
3) Kirjakauppojen laajassa valikoimassa kirja ei varmaankaan jää huomiotta.
4) Euroopassa sellaiset käsitteet kuin valta ja vallankäyttö ovat kauan puhuttaneet tutkijoita, taiteilijoita sekä rivikansalaisia.
5) Valtava määrä tuttujen henkilöjen puheita, kirjeitä ja haastatteluja on käsitellyt kirjan aihetta viime vuosina.
6) Yhdysvalloissa kirja ei kuitenkaan herättänyt isoa huomiota.
7) Ehkä syynä tähän on se, että kansanvalta ei esiintynyt tekstissä.
8) Joka tapauksessa Valkoinen talo ei ole kommentoitunut asiasta.
9) Ilmeisesti vallan nykytila ei tunnu amerikkalaisista poliitikoista huolestuttavalta.
10) Sen sijaan he seuraavat edelleen oman valtakuntansa taloutta.
| Hakulause | Tulokset (virkkeen numero ja sopiva sana) | Selitys |
|---|---|---|
| valta | 1 (vallasta), 4 (valta), 5 (valtava), 6 (Yhdysvalloissa), 7 (kansanvalta), 9 (vallan), 10 (valtakuntansa) | ”valta” on tässä haussa perusmuoto tai sen osa, esim. yhdyssanan alku- (virke 10) tai loppuosa (virkkeet 6 ja 7) |
| ^valta | 1 (vallasta), 4 (valta), 5 (valtava), 9 (vallan), 10 (valtakuntansa) | ”valta” on edelleen perusmuoto, joka löytyy sanan alusta mutta ei välttämättä ole koko sana (virkkeet 5 ja 10) |
| valta$ | 1 (vallasta), 4 (valta), 6 (Yhdysvalloissa), 7 (kansanvalta), 9 (vallan) | ”valta” on edelleen perusmuoto, joka löytyy sanan lopusta mutta ei välttämättä ole koko sana (virkkeet 6 ja 7) |
| ^valta$ | 1 (vallasta), 4 (valta), 9 (vallan) | ”valta” on edelleen perusmuoto eikä sanaan kuulu mitään muuta |
| valta! | 4 (valta) | ”valta” on tekstissä oleva tarkka sanamuoto, taivutusmuotoja ei oteta mukaan |
| vallasta | - | ”vallasta” etsitään perusmuotona, vaikka se ei ole minkään sanan perusmuoto |
| vallasta! | 1 (vallasta) | ”vallasta” etsitään juuri tässä muodossa |
| val | 1 (vallasta), 2 (vallitsemana), 3 (valikoimassa), 4 (valta), 5 (valtava), 6 (Yhdysvalloissa), 7 (kansanvalta), 8 (Valkoinen), 9 (vallan), 10 (valtakuntansa) | ”val” kuuluu eri sanojen, myös yhdyssanojen, perusmuotoihin |
| ^val | 1 (vallasta), 2 (vallitsemana), 3 (valikoimassa), 4 (valta), 5 (valtava), 8 (Valkoinen), 9 (vallan), 10 (valtakuntansa) | ”val” on edelleen perusmuodon osa, joka löytyy sanan alusta |
| vallita | 2 (vallitsemana) | ”vallita” on perusmuoto, joka esiintyy täällä partisiippina |
| "valta kirja" | 1 (kirja, vallasta), 5 (valtava, kirjan), 6 (Yhdysvalloissa, kirja) | Molemmat sanat etsitään perusmuotona ja molempien on oltava samassa virkkeessä |
| valta | kirja 1 (kirja), 3 (kirjakauppojen), 4 (valta), 5 (kirjan), 6 (Yhdysvalloissa), 7 (kansanvalta), 9 (vallan), 10 (valtakuntansa) | Molemmat sanat etsitään perusmuotona, mutta ainakin yhden on oltava virkkeessä |
| 'valla' | 1 (vallasta), 4 (vallankäyttö), 9 (vallan) | ”valla” löytyy virkkeen tekstistä juuri tässä muodossa; perusmuoto ei vaikuta |
| valta|type=NOUN|Case=Nom,Gen | 4 (valta), 7 (kansanvalta), 9 (vallan), 10 (valtakuntansa) | ”valta” on perusmuodon osa ja koko sana on nominatiivissa tai genetiivissä oleva substantiivi |
| valta$|type=NOUN|Case=Nom,Gen | 4 (valta), 7 (kansanvalta), 9 (vallan) | ”valta” on edelleen perusmuodon osa ja sana päättyy siihen |
| *|type=NOUN|Case=Ine | 1 (Helsingissä), 3 (valikoimassa), 4 (Euroopassa), 6 (Yhdysvalloissa), 7 (tekstissä), 8 (tapauksessa) | Mikä tahansa substantiivi inessiivissä |